Primo, Primo Central Index, and SFX: How do they work together?
Primo is a bit tricky to understand, since it uses data from two different sources: The Primo Central Index (usually referred to as “PCI“) and the holdings extract from our SFX holdings (Google Scholar extract).
- A Primo search first searches the PCI to obtain citations (i.e. metadata). Only the slice of the PCI that is activated for a user’s location is searched. This is important: For example, a Queens College user only searches those e-resource collections that have been activated in the PCI for Queens College.
- In a second step, these results are matched against the current holdings in the SFX knowledge base. This holdings information (i.e the range of a subscription to a journal) is contained in a school’s Google Scholar extract. If Primo finds a match in the Google Scholar extract for a citation it found, it can safely determine that fulltext is available for the citation (and thus display the “View Online” tab).
Here’s a sample display of a Primo record from the Ex Libris training materials. It explains where the different parts of the records display are coming from:

Let’s apply this to a sample record from CUNY’s OneSearch:
(URL: http://onesearch.cuny.edu/CUNY:TN_medline17776449)
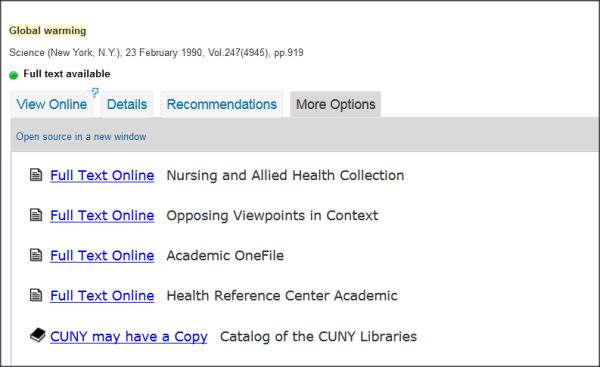
- The citation information at the top (Global warming, Science, New York, etc.) is coming from an activated collection the PCI.
- The line “Full text is available” is generated based on information in the Google Scholar extract
- The “View Online” tab and the information under the “More Options” tab are included because the journal “science” is active in SFX. What you see under “More Options” is an actual “Find it!” menu based on this citation.
So it’s important to understand that both parts, a school’s active collections in the PCI, and a school’s holdings in SFX have to be up-to-date for this to work properly.
Hope this post was helpful,
Roland